
Observability ist der Schlüssel zu stabilen IT-Systemen und deutlich mehr als klassisches Monitoring. Sie macht komplexe IT-Landschaften nachvollziehbar und stabil.
Wir zeigen nicht nur fünf Do’s und Don’ts, die kleine und mittelständische Unternehmen beachten sollten, sondern erklären auch, was Observability überhaupt ist und was der Unterschied zum Monitoring ist. Lesen Sie weiter und bleiben informiert.
Unser Beitrag über Observability im Überblick:
- Was ist Observability?
- Unterschied: Observability vs. Monitoring
- Drei Säulen der Observability
- Do’s & Don’ts als Leitplanken
- Do #1: Alarme mit Sinn statt Lärm um Nichts
- Do #2: Alerts mit Kontext anreichern
- Do #3: Schweregrade konsequent nutzen
- Do #4: Observability frühzeitig integrieren
- Do #5: Metriken, Logs und Traces verbinden
- Don’t #1: Monitoring mit Observability verwechseln
- Don’t #2: Tool-Sprawl vermeiden
- Don’t #3: Nicht alles und jeden alarmieren
- Don’t #4: Dashboards ohne Kontext bauen
- Don’t #5: Observability nicht als Projekt denken
- Herausforderungen bei der Einführung
- Observability in DevOps und SRE
- Observability: KI und Automatisierung
- Vorteile für KMU im Überblick
- Observability als kontinuierlicher Prozess
Was ist Observability?
Observability – auf Deutsch „Beobachtbarkeit“ – beschreibt die Fähigkeit, den internen Zustand eines IT-Systems allein anhand seiner äußeren Signale zu verstehen. Der Begriff stammt ursprünglich aus der Regelungstechnik und hat sich in den vergangenen Jahren im IT-Betrieb etabliert. Ursprung des Wortes ist das englische „to observe“ (beobachten).
Während Monitoring vordefinierte Kennzahlen wie CPU-Auslastung oder Speicherverbrauch überwacht, geht Observability einen Schritt weiter. Sie nutzt Telemetriedaten wie Logs, Metriken und Traces, um komplexe Zusammenhänge sichtbar zu machen. Ihr Ziel ist es, nicht nur festzustellen, dass ein Problem vorliegt, sondern auch zu verstehen, warum es auftritt.
Für Unternehmen bedeutet das: Observability schafft Transparenz über Anwendungen, Infrastrukturen und Benutzerinteraktionen in Echtzeit. Gerade in modernen IT-Landschaften mit Cloud-Diensten, Microservices und verteilten Systemen wird diese Fähigkeit unverzichtbar. Nur wer die Ursachen von Störungen schnell erkennt, kann die Stabilität und Sicherheit seiner Systeme dauerhaft gewährleisten.

Observability macht komplexe Systeme durch Logs, Metriken und Traces verständlich. Bild: ChatGPT (Bild erstellt mit KI)
Unterschied: Observability vs. Monitoring
Monitoring und Observability werden zwar oft gleichgesetzt, sie unterscheiden sich jedoch grundlegend. Folgende Differenzen gibt es:
- Monitoring verfolgt definierte Kennzahlen wie Auslastung, Antwortzeiten oder Verfügbarkeit. Es beantwortet die Frage: „Funktioniert das System innerhalb bestimmter Grenzwerte?“
- Observability geht weiter. Statt nur Schwellenwerte zu prüfen, korreliert sie verschiedene Datenquellen und macht so Ursachen sichtbar. Sie beantwortet die Frage: „Warum verhält sich das System so?“.
Damit liefert die Beobachtbarkeit kontextreiche Einblicke, die Monitoring allein nicht bieten kann. Ein Beispiel ist: Ein klassisches Monitoring-System meldet, dass die CPU-Auslastung auf 95 % gestiegen ist. Observability zeigt zusätzlich, dass ein fehlerhaftes Deployment im Microservice X die Ursache ist, weil es über Traces, Logs und Metriken die gesamte Fehlerkette nachvollzieht.
Für kleine und mittelständische Unternehmen bedeutet das: Monitoring erkennt Symptome, Observability deckt Ursachen auf. In dynamischen IT-Umgebungen mit Cloud-Architekturen, Containern oder hybriden Systemen ist dieser Unterschied entscheidend, um nicht nur Probleme zu registrieren, sondern sie nachhaltig zu beheben.
Drei Säulen der Observability
Das Fundament jeder Observability-Strategie bilden drei Arten von Telemetriedaten: Logs, Metriken und Traces. Erst ihre Kombination liefert den nötigen Kontext, um Ursachen zu verstehen und Probleme effizient zu beheben.
- Logs sind detaillierte Protokolle einzelner Ereignisse, meist mit Zeitstempel. Sie geben Aufschluss darüber, was zu einem bestimmten Zeitpunkt im System passiert ist – etwa Fehlermeldungen, Statusänderungen oder Nutzeraktionen.
- Metriken erfassen quantifizierbare Werte wie CPU-Auslastung, Speichernutzung oder Latenzen. Sie ermöglichen es, den Zustand von Anwendungen und Infrastrukturen über längere Zeiträume hinweg zu bewerten.
- Traces bilden den Weg einer Anfrage durch das System ab – von der Benutzeroberfläche bis zur Datenbank. Damit lassen sich Abhängigkeiten zwischen Services sichtbar machen und Engpässe präzise lokalisieren.
In der Praxis zeigt sich: Einzelne Datentypen liefern nur Teilinformationen. Erst durch die zentrale Korrelation von Logs, Metriken und Traces entsteht ein vollständiges Bild. So können IT-Teams in Echtzeit erkennen, wie Fehler durch die Architektur wandern und wo die eigentliche Ursache liegt.
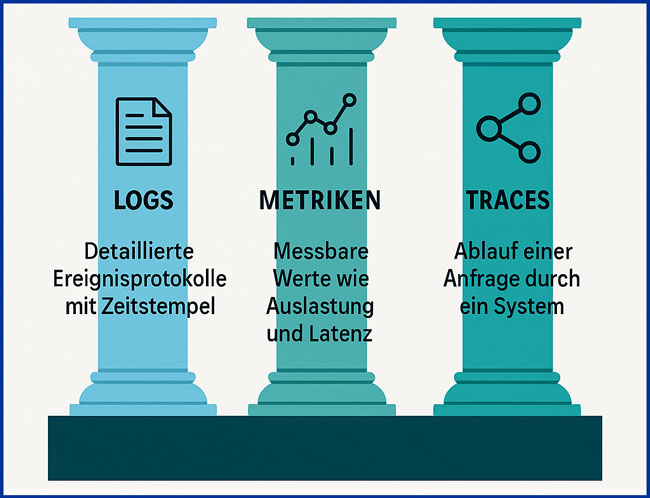
Logs, Metriken und Traces bilden das Fundament jeder Observability-Strategie. Bild: ChatGPT (Bild erstellt mit KI)
Do’s & Don’ts als Leitplanken
In der Theorie klingt Observability eindeutig: Systeme beobachten, Daten sammeln, Ursachen verstehen. In der Praxis aber scheitern viele Unternehmen nicht an den Tools, sondern an fehlender Struktur und Priorisierung. Zu viele Alarme ohne Kontext, Datensilos oder einmalige Projekte führen dazu, dass Observability ihren Nutzen verliert.
Die folgenden fünf Do’s und fünf Don’ts zeigen praxisnah, worauf es ankommt. Sie helfen, typische Fehler zu vermeiden und Observability als dauerhaften Bestandteil von IT-Strategien zu verankern, denn neben klaren Handlungsempfehlungen gibt es auch Stolperfallen, die den Erfolg einer Observability-Strategie gefährden. Viele davon entstehen nicht durch fehlende Technik, sondern durch falsches Verständnis oder unklare Prozesse. Ob Tool-Wildwuchs, überflüssige Alarme oder das Denken in einmaligen Projekten – diese Fehler sorgen dafür, dass Observability ihren eigentlichen Nutzen verliert. Mit Folgen: hohe Kosten, langsame Reaktionszeiten und eine IT, die im Ernstfall nicht zuverlässig funktioniert.
Für kleine und mittelständische Unternehmen sind die Dos und Don’ts ein klarer Handlungsrahmen, um mit überschaubarem Aufwand mehr Stabilität, Transparenz und Sicherheit in ihre Systeme zu bringen.
Do #1: Alarme mit Sinn statt Lärm um Nichts
Alarme sind nur dann hilfreich, wenn sie echte Probleme anzeigen. In vielen Unternehmen erzeugen schwellenwertbasierte Alerts jedoch ein Rauschen, das mehr Verwirrung als Nutzen bringt. Ein Beispiel: Ein Alarm für hohe CPU-Auslastung löst Panik aus, obwohl die eigentliche Ursache ein fehlerhaftes Deployment ist.
Stattdessen sollten Alerts symptombasiert konfiguriert werden. Das bedeutet: Warnungen orientieren sich nicht allein an technischen Grenzwerten, sondern an Auswirkungen auf die Nutzererfahrung, Fehlerquoten oder Antwortzeiten. So erkennen Teams schneller, wo tatsächlich Handlungsbedarf besteht.
Gerade in komplexen Microservice-Umgebungen verhindert diese Herangehensweise die berüchtigte „Alarmmüdigkeit“. Wer bei jedem kleinen Ausschlag benachrichtigt wird, reagiert irgendwann gar nicht mehr. Mit einer klaren Fokussierung auf Symptome behalten Teams den Überblick und können im Ernstfall gezielt eingreifen.

Kontext statt Chaos: Nur mit klaren Labels und Beschreibungen helfen Alarme wirklich weiter. Bild: ChatGPT (Bild erstellt mit KI)
Do #2: Alerts mit Kontext anreichern
Ein Alarm ohne Hintergrundinformation ist wie ein Stoppschild ohne Richtung. Er signalisiert, dass etwas nicht stimmt, hilft aber nicht beim Finden der Ursache. Genau hier setzt eine gute Observability-Strategie an: Alarme brauchen Kontext.
Dazu gehört eine saubere Strukturierung mit Labels wie Service, Komponente oder Umgebung. Auch sprechende Titel und Beschreibungen sind entscheidend. Statt einer anonymen Meldung „Alert #457“ sollte die Benachrichtigung etwa lauten: „Datenbank-Zugriffsfehler in EU-West-1, Service X“.
Durch diese Anreicherung können Teams sofort einschätzen, welche Systeme betroffen sind und wo sie mit der Fehleranalyse ansetzen müssen. Besonders in interdisziplinären Teams aus Entwicklung und Betrieb reduziert klarer Kontext Missverständnisse und spart wertvolle Zeit.
Die Erfahrung zeigt: Ohne einheitliches Benennungskonzept bleiben Alarme abstrakt. Mit konsequent gepflegten Labels und Klartext gewinnen sie dagegen an Aussagekraft – und helfen, schnell die richtigen Maßnahmen einzuleiten.
Do #3: Schweregrade konsequent nutzen
Wenn jeder Alarm den gleichen Stellenwert hat, verliert das gesamte System an Glaubwürdigkeit. Ohne klare Unterscheidung werden Warnungen entweder ignoriert oder überdramatisiert – beides ist riskant.
Eine wirksame Observability-Strategie setzt deshalb auf Schwere-Stufen. Typische Kategorien sind etwa Info, Warning und Critical. Entscheidend ist nicht nur die Einteilung, sondern auch die klare Definition, welche Reaktion damit verbunden ist. Ein „Critical“-Alarm löst beispielsweise sofort eine Eskalation aus, während ein „Warning“ in den täglichen Review einfließt.
Diese Regeln müssen zwischen Entwicklung, Betrieb und Management abgestimmt und verbindlich dokumentiert sein. Nur so entsteht Vertrauen in die Alarmierungskette. Gerade in Teams mit Schichtbetrieb oder hoher Fluktuation reduziert eine durchdachte Schwere-Klassifikation das Risiko, dass kritische Probleme übersehen werden.

Observability funktioniert nur mit klar definierten Schwere-Stufen: Info, Warning und Critical. Bild: ChatGPT (Bild erstellt mit KI)
Do #4: Observability frühzeitig integrieren
Viele Unternehmen schieben Observability auf die lange Bank. Logging, Tracing und Metriken werden erst nachträglich eingebaut – oft dann, wenn bereits ein kritischer Vorfall aufgetreten ist. Das Ergebnis: fehlende Vergleichsdaten, hoher Aufwand und im Ernstfall lange Ausfallzeiten.
Der bessere Weg ist, Observability von Anfang an in den Entwicklungsprozess zu integrieren. Offene Standards wie OpenTelemetry bieten dabei die nötige Flexibilität, um herstellerunabhängig und zukunftssicher zu arbeiten. So lassen sich Anwendungen, Container und Infrastrukturen direkt bei der Einführung instrumentieren, statt später mühsam nachzurüsten.
Für kleine und mittelständische Unternehmen hat dieser Ansatz einen klaren Vorteil: Er spart Kosten und verhindert blinde Flecken. Frühzeitige Instrumentierung sorgt dafür, dass historische Daten vorliegen, wenn es darauf ankommt – und dass Observability nicht als Zusatz, sondern als fester Bestandteil der IT-Architektur verstanden wird.
Do #5: Metriken, Logs und Traces verbinden
Einzelne Signale liefern nur Fragmente der Wahrheit. Metriken zeigen Trends, Logs geben Details, und Traces machen Abläufe sichtbar. Erst wenn diese drei Säulen zentral korreliert werden, entsteht ein vollständiges Bild des Systemverhaltens.
Eine gute Observability-Plattform verknüpft daher alle Datenströme in Echtzeit und ergänzt sie um Topologie-Informationen. So lässt sich nicht nur feststellen, dass ein Fehler existiert, sondern auch, wie er sich durch die Architektur bewegt und welche Services betroffen sind.
In der Praxis nutzen viele Unternehmen jedoch verschiedene Tools für Logs, Metriken und Traces – ohne echte Verbindung. Das führt zu Silos und Teilwahrheiten. Die Folge: Teams verbringen Zeit mit Kontextwechseln, anstatt die Ursache zu lösen. Eine zentrale Korrelation spart Aufwand und ermöglicht eine schnelle Root-Cause-Analyse, was gerade für kleinere IT-Abteilungen entscheidend ist.
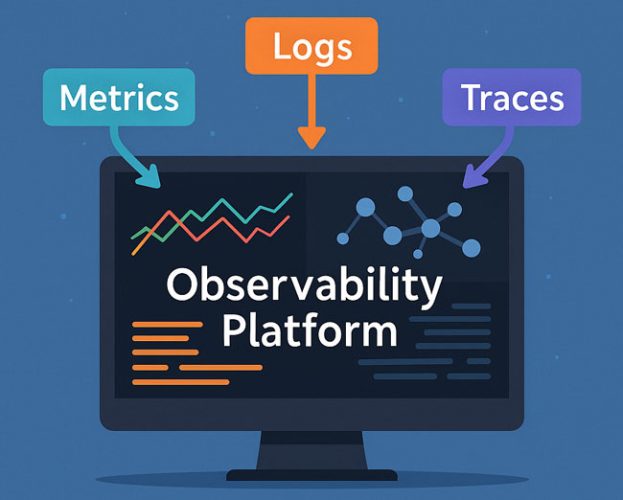
Eine einzige Observability-Plattform vereint Logs, Metriken und Traces, sodass ein vollständiges Bild des Systemverhaltens entsteht. Bild: ChatGPT (Bild erstellt mit KI)
Don’t #1: Monitoring mit Observability verwechseln
Ein häufiger Fehler besteht darin, Observability als erweitertes Monitoring zu betrachten. Monitoring beantwortet die Frage, ob ein System funktioniert. Observability dagegen zeigt, warum es funktioniert oder eben nicht.
Wer diesen Unterschied ignoriert, bekämpft Symptome statt Ursachen. Ein Dashboard mit Schwellenwerten und Verfügbarkeitsmetriken mag nützlich sein, liefert aber keine Einsicht in kausale Zusammenhänge. Ohne diese Tiefe bleibt die IT blind für schleichende Probleme, die erst spät eskalieren.
Das bedeutet, Sie dürfen Observability nicht als neues Tool oder hübsches Interface verstehen, sondern als strategisches Framework. Es geht um ein Denken in Zusammenhängen und Ursachen – und darum, IT-Betrieb nicht nur reaktiv, sondern proaktiv zu gestalten.
Don’t #2: Tool-Sprawl vermeiden
Viele Unternehmen sammeln im Laufe der Zeit eine Vielzahl spezialisierter Tools an – für Logging, für Metriken, für Traces, für Dashboards. Das Problem: Jedes Tool bildet nur einen Teilbereich ab. Die Folge sind Datensilos, Kontextverluste und im Ernstfall offene Browser-Tabs statt klarer Antworten.
Gerade kleine und mittelständische Unternehmen laufen Gefahr, ihre IT-Landschaft durch diesen Tool-Sprawl unnötig zu verkomplizieren. Statt Transparenz entsteht Chaos, und die Fehlersuche kostet mehr Zeit, als sie spart.
Die bessere Lösung ist eine zentrale Observability-Plattform, die alle drei Säulen – Metriken, Logs und Traces – integriert und zusätzlich Kontextinformationen wie Abhängigkeiten oder Nutzererfahrungen einbindet. So behalten Teams den Überblick und vermeiden redundante Tools, die weder effizient noch kostensparend sind (siehe Do #5).

u viele Tools führen zu Chaos – eine zentrale Plattform schafft Klarheit. Bild: ChatGPT (Bild erstellt mit KI)
Don’t #3: Nicht alles und jeden alarmieren
Ein weiteres Problem ist die sogenannte Alarmmüdigkeit. Wenn jedes Ereignis einen Pager auslöst, verlieren Teams das Vertrauen in die Alarme. Irgendwann wird nicht mehr reagiert – selbst wenn es wirklich kritisch ist (siehe Do #1).
Stattdessen braucht es klare Eskalationsstufen. Nur Vorfälle, die sofortiges Eingreifen erfordern, dürfen einen kritischen Alarm auslösen. Weniger dringende Hinweise sollten in Dashboards, täglichen Reports oder automatisierten Nachrichten landen.
Die Praxis zeigt: Alarmmüdigkeit ist kein technisches, sondern ein kulturelles Problem. Wenn alles eskaliert wird, weil „sonst niemand reagiert“, hört irgendwann niemand mehr zu. Für KMU bedeutet das: Weniger ist mehr. Wenige, aber gezielte Alarme sorgen dafür, dass im Ernstfall schnell gehandelt wird – und dass Teams den Warnungen vertrauen.
Don’t #4: Dashboards ohne Kontext bauen
Viele IT-Teams investieren viel Zeit in bunte Dashboards, die am Ende nur Einzelwerte darstellen. Das sieht zwar ordentlich aus, liefert aber oft keine echten Erkenntnisse. Ohne Kontext bleibt unklar, welche Zusammenhänge bestehen und welche Auswirkungen ein Vorfall wirklich hat.
Ein wirksames Dashboard beantwortet dagegen konkrete Fragen: Welche Services hängen zusammen? Welche Abhängigkeiten bestehen zwischen Anwendungen und Infrastruktur? Wie beeinflusst ein Fehler die Nutzererfahrung? Nur mit diesen Informationen lassen sich sinnvolle Entscheidungen treffen.
Besonders hilfreich sind interaktive Dashboards mit Drill-Down-Funktionalitäten. Sie ermöglichen es, von einer auffälligen Kennzahl direkt zur zugrunde liegenden Ursache zu navigieren. Visualisierungen allein reichen nicht – entscheidend ist die Verbindung von Daten, Kontext und Handlungsmöglichkeiten. Fazit: Dashboards müssen handlungsorientiert sein und Teams dabei unterstützen, Probleme schneller und gezielter zu lösen.

Dashboards müssen Zusammenhänge zeigen – nicht nur bunte Einzelwerte. Bild: ChatGPT (Bild erstellt mit KI)
Don’t #5: Observability nicht als Projekt denken
Ein häufiger Fehler ist es, Observability als einmaliges Projekt zu betrachten. Systeme entwickeln sich jedoch ständig weiter – durch neue Deployments, Updates oder geänderte IT-Tnfrastrukturen. Wer Observability nach der Einführung nicht kontinuierlich pflegt, arbeitet schon bald mit veralteten Daten und falschen Annahmen.
Observability ist kein „Deliverable“, sondern ein dauerhafter Arbeitsmodus. Dazu gehören regelmäßige Reviews von Alarmen und Dashboards ebenso wie die Anpassung an neue Architekturen und Geschäftsprozesse. Nur so bleibt die Transparenz über Systeme und Abhängigkeiten erhalten.
Das bedeutet, dass Observability Teil der alltäglichen Betriebs- und Entwicklungsprozesse sein sollte. Mit klaren Verantwortlichkeiten und wiederkehrenden Feedbackschleifen wird sie zum festen Bestandteil der IT-Strategie – statt zu einem Strohfeuer, das nach kurzer Zeit verpufft.
Herausforderungen bei der Einführung
Die Umsetzung von Observability bringt für Unternehmen spürbare Vorteile, ist aber auch mit typischen Hürden verbunden. Gerade kleine und mittelständische Unternehmen sollten diese Stolpersteine kennen, um sie frühzeitig zu adressieren.
- Datenvolumen: Observability erzeugt eine enorme Menge an Logs, Metriken und Traces. Ohne klare Filter- und Aggregationsstrategien können Teams schnell den Überblick verlieren und Ressourcen unnötig belasten.
- Komplexität: Moderne IT-Landschaften bestehen aus Microservices, hybriden Clouds und dynamischen Deployments. Eine durchdachte Architektur ist nötig, um Observability sinnvoll einzubetten, anstatt punktuell einzelne Tools zu ergänzen.
- Tool-Silos: In vielen Unternehmen arbeiten Abteilungen mit unterschiedlichen Plattformen. Das führt zu redundanten Daten, Kontextverlust und widersprüchlichen Analysen. Eine zentrale Lösung ist entscheidend, um diese Silos aufzubrechen.
- Prozesse und Kultur: Technik allein reicht nicht. Teams brauchen abgestimmte Regeln für Alarme, Eskalationen und Reviews. Ohne gemeinsame Standards bleibt Observability Stückwerk und verliert an Wirkung.
Diese Herausforderungen sind lösbar – vorausgesetzt, Observability wird als strategisches Thema betrachtet und nicht als technisches Nebenprojekt.

Komplexität, Datenvolumen und Silos gehören zu den größten Stolpersteinen bei Observability. Bild: ChatGPT (Bild erstellt mit KI)
Observability in DevOps und SRE
DevOps-Teams und Site Reliability Engineers (SRE) arbeiten mit kurzen Release-Zyklen, automatisierten Deployments und komplexen Microservice-Architekturen. In diesem Umfeld ist Observability unverzichtbar. Sie liefert das kontinuierliche Feedback, das nötig ist, um schnelle Änderungen sicher umzusetzen.
Durch die Kombination von Logs, Metriken und Traces können DevOps-Teams Engpässe früh erkennen und beheben – bevor sie die Nutzererfahrung beeinträchtigen. Observability unterstützt außerdem beim Incident-Management, da Ursachen schneller identifiziert und dokumentiert werden.
Für SRE-Teams ist Observability die Basis, um Service Level Objectives (SLOs) und Service Level Indicators (SLIs) zuverlässig zu überwachen. Nur mit umfassender Transparenz lässt sich die Balance zwischen Innovation und Stabilität halten.
Gerade kleine und mittelständische Unternehmen profitieren: Sie können mit Observability die Qualität ihrer IT-Services verbessern, ohne große Teams oder Ressourcen aufbauen zu müssen. Die Methode wird so zu einem Werkzeug, das Geschwindigkeit und Verlässlichkeit gleichermaßen ermöglicht.
Observability KI und Automatisierung
Mit klassischen Methoden ist die Menge an Telemetriedaten aus modernen IT-Landschaften kaum noch beherrschbar. Hier setzen Künstliche Intelligenz (KI) und Automatisierung an. Sie helfen, aus Milliarden von Datenpunkten Muster zu erkennen und echte Probleme von belanglosem Rauschen zu unterscheiden.
KI-gestützte Observability-Systeme nutzen Verfahren wie Machine Learning (ML), um Anomalien automatisch zu identifizieren. So können Vorfälle schon erkannt werden, bevor sie sich auf die Nutzererfahrung auswirken. Zusätzlich ermöglichen AIOps-Plattformen (Artificial Intelligence for IT Operations), Alarme zu priorisieren und repetitive Aufgaben wie das Erstellen von Tickets oder das Anstoßen von Standardmaßnahmen zu automatisieren.
Ein weiterer Schritt ist die automatisierte Remediation: Systeme können vordefinierte Gegenmaßnahmen selbst ausführen – etwa einen Service neu starten oder zusätzliche Ressourcen bereitstellen. Dadurch verkürzt sich die Zeit bis zur Behebung (MTTR) erheblich.
Mit KI und Automatisierung wird Observability effizienter und weniger personalintensiv. Anstatt alle Details manuell zu prüfen, können IT-Teams sich auf kritische Entscheidungen konzentrieren, während die Plattform Routineaufgaben übernimmt.

KI-gestützte Observability filtert Rauschen, erkennt Anomalien und automatisiert Standardmaßnahmen. Bild: ChatGPT (Bild erstellt mit KI)
Vorteile für KMU im Überblick
Observability ist kein Luxus großer Konzerne, sondern bringt auch handfeste Vorteile für KMU:
- Weniger Ausfälle: Durch schnelle Ursachenanalyse sinken Ausfallzeiten, und Systeme bleiben stabil. Das schützt nicht nur die IT, sondern auch Geschäftsprozesse und Kundenzufriedenheit.
- Bessere Nutzererfahrung: Indem Fehlerquellen frühzeitig erkannt werden, steigt die Qualität von Anwendungen und Services. Langsame Reaktionszeiten oder Funktionsstörungen lassen sich gezielt reduzieren.
- Zeit- und Kostenersparnis: Automatisierte Analysen und klare Alarmierungen sparen wertvolle Arbeitszeit. IT-Teams müssen weniger manuell nach Ursachen suchen und können sich auf strategische Aufgaben konzentrieren.
- Transparenz in komplexen Systemen: Gerade bei hybriden oder cloudbasierten Architekturen sorgt Observability für Durchblick. Abhängigkeiten werden sichtbar, und IT-Entscheidungen lassen sich faktenbasiert treffen.
Für KMU ergibt sich daraus ein klarer Wettbewerbsvorteil: Mit überschaubarem Aufwand verbessern sie die Verfügbarkeit ihrer Systeme und stärken die Sicherheit – ohne teure Großprojekte starten zu müssen.
Observability als kontinuierlicher Prozess
Zuammenfassend lässt sich sagen: Observability ist weit mehr als ein Trendbegriff. Sie entscheidet darüber, ob IT-Systeme stabil, nachvollziehbar und zukunftssicher bleiben. Wer Observability richtig einführt, erkennt nicht nur Fehler schneller, sondern versteht auch deren Ursachen – und kann daraus konkrete Verbesserungen ableiten. Damit wird Observability zu einem festen Bestandteil der IT-Strategie – und nicht zu einem Strohfeuer, das nach der ersten Implementierung verpufft.
Aber: Eine erfolgreiche Observability-Strategie entsteht nicht über Nacht. Sie setzt technisches Know-how, klare Prozesse und kontinuierliche Anpassungen voraus. Besonders kleine und mittelständische Unternehmen stehen hier vor der Herausforderung, ihre begrenzten Ressourcen effizient einzusetzen und gleichzeitig ein stabiles IT-Fundament zu schaffen.
Genau dabei unterstützt PC-SPEZIALIST. Von der Einrichtung zentraler Monitoring- und Observability-Lösungen über die Integration von Logging, Metriken und Traces bis hin zur Absicherung Ihrer gesamten IT-Infrastruktur erhalten Sie professionelle Begleitung aus einer Hand. Auch Themen wie Backup, IT-Sicherheit oder Cloud-Lösungen fließen in ein ganzheitliches Konzept ein, das Transparenz und Stabilität dauerhaft sicherstellt.
Mit PC-SPEZIALIST gewinnen Sie nicht nur Einblick in den Zustand Ihrer Systeme, sondern auch die Sicherheit, dass im Ernstfall schnell reagiert werden kann. So schaffen Sie die Basis für zuverlässige Geschäftsprozesse, zufriedene Kunden und eine zukunftssichere IT. Nehmen Sie gern Kontakt zu Ihrem PC-SPEZIALIST in Ihrer Nähe auf und lassen Sie sich beraten.
_______________________________________________
Quellen: it-business, ibm, servicenow, newrelic, cloudcomputing-insider, Pexels/cottonbro studio (Headerbild)
Schreiben Sie einen Kommentar